
Getting Started with Chat Copilot Generative AI Development
AI-Assisted Proofreading
All articles on this site are written by me. I use AI tools solely for proofreading and editing assistance to ensure clarity and accuracy.
Hello friends, welcome back to my blog, and happy Friday. Today I want to continue our journey into Generative AI Chat Copilot development. I had planned to write a different article today, but I think this topic is more appropriate, to give an overview of the different building blocks in developing a Chat Copilot. It’s possible that some of this information applies past a simple Chat/Copilot example, but since that’s all I’ve really been researching, I wanted to make that the focus and I’ll explore other use cases where Generative AI can be useful (and how to develop those use cases) in the future. If you missed my first blog post on this topic: https://dylanyoung.dev/insights/create-a-local-chat-assistant-with-openai-and-microsoft-chat-copilot/, make sure you check that out, since I covered installing the Microsoft Chat Copilot open source repository on your local machine (which is great if you want to build a chat copilot for your own purposes).
This blog post, however, will focus on the different pieces that were represented in Microsoft’s Chat Copilot example, or some other common elements when you are building a chat copilot. I’m going to call out below, where Microsoft’s offerings fit in and then describe some of the more mainstream options that are available. In a future blog post, I’ll look through each specific piece and do a deep dive comparison of the options.
Before we explore the different pieces of a Chat Copilot Generative AI application, I wanted to briefly describe the flow that is required. I found the following very helpful in describing custom development with a Chat interface:
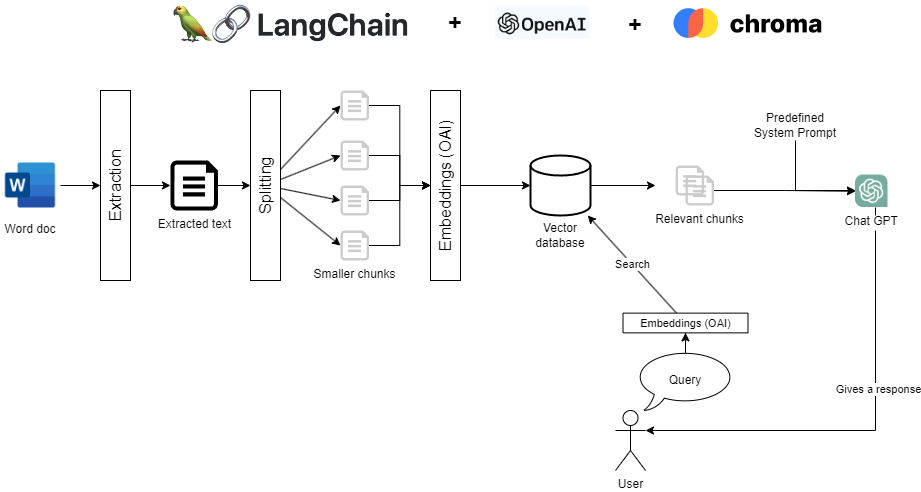
Let's take a few moments to break down the diagram above and delve a little deeper into each of its parts. We'll also discuss some of the options you may have when building these components of the application.
Large Language Models (LLM)
As previously mentioned, the LLM is the most important part of any Generative AI application. While it is possible to use these LLMs directly with ChatGPT (https://chat.openai.com/), it may not always be the most useful option. Additionally, there are many LLMs available beyond just OpenAI's models, such as LLaMa (Meta) and BERD (Google), each with different use cases. Some are more specific to chat interfaces, while others are more code or multimedia specific.
If you are new to this field, it's worth taking a look at https://huggingface.co/, which is a website that lists the different models and allows for filtering based on criteria such as licensing and model types. Having a solid list of available models is a great place to start, and it's important to note that you may use multiple models in your specific application to build better and more rounded applications.
It's important to note that in many cases, using multiple LLMs simultaneously can be helpful in improving your application's ability to return relevant information.
For those who read my first article on setting up the Microsoft Chat Copilot, that open-source project allows you to use either Azure Open AI’s LLMs or Open AIs LLMs. It is also probably possible that you could connect to other similar LLMs as well, just some modifications may be required to connect/authenticate to those different systems.
Embeddings
An Embedding is a machine-readable representation of text that is converted into a multi-dimensional array of float numbers. These numbers represent a vector, and similar phrases or words will have very similar vectors. By collecting and storing these vectors, an application can match up similar phrases that are searched for in the future by users.
Vector Database/Store or Search
The Embeddings or Vectors are saved in a database, typically a database specialized in storing vectors, like a Vector Store/Database such as Azure Cognitive Search, Chroma, or Pine Cone (there are many more to choose from, but we’ll start with some of the most popular ones here). Think of a Vector database and the creation of Embeddings as creating a long-term memory store for our application, which helps it to perform better over time.
To make the most of storing large amounts of vectors and get faster results, you'll need a Vector store designed specifically for that purpose. One important aspect of such a store is effective indexing of the data. When you map a user prompt to a vector and calculate the closest distance for vectors in the database, the multi-dimensional requests can take a lot of time. While you could store vectors anywhere, even in a notepad file, a Vector store designed for storing vectors will provide many benefits.
Another popular topic that frequently arises when discussing Vector Searching (such as using Azure Cognitive Search, which can act as both a Vector database and a Search index) is the ability to perform Hybrid Searches. Hybrid search in the context of Generative AI involves using both traditional word searching and vector searching to improve the relevance of search results for a given query. This approach combines the strengths of both technologies to provide more accurate and useful results. For example, a hybrid search for a chat copilot application could involve using vector searching to match similar phrases or words and then refining the results using traditional word-searching techniques.
Large Language Model SDK/Orchestrators
Honestly, there doesn’t seem to be an official name to describe these from my research. Often times I’ve seen these lumped into the LLM category, however, that just doesn’t make sense. These tools do not act like an LLM and instead work in the middle of everything in the Chat Copilot application. When a prompt in your chat interface comes in, your request is handled first by the LLM SDK/Orchestrator, which can then add additional context to that request. An example, is that maybe you want to have the LLM respond in a different language or just a different tense, this is just one example of what the Orchestrator can handle for the application. Another use case is combining the initial prompt with additional context about the user, such as previous prompts they entered, or using some of the embedding data to help the LLM respond with more focused content. I will cover this topic further in upcoming blogs and walk through specific use cases.
In our previous blog, where we set up the open-source Microsoft Chat Copilot (https://github.com/microsoft/chat-copilot), its orchestrator was handled by Microsoft’s specific option called Semantic Kernel. This SDK can be extended with .Net which is one of the main reasons you would choose to use Semantic Kernel over other potential options if you are a .Net shop. Some drawbacks however might be that you need to host additional services to handle this orchestration layer, as well as it’s not as popular or has quite as many features as the next option I’m going to describe in the next paragraph.
Another more popular option is to use an SDK called LangChain (mentioned above in our diagram). This SDK is built to handle more use cases (detailed below) and even works with Typescript/Node, making it a better option in many cases, because it can be used alongside a more modern Next.js application (https://vercel.com/templates/next.js/langchain-starter). I will admit the Vercel starter kit doesn’t look quite as nice as the Microsoft Chat Copilot, but there are many more options and it’s super easy to spin that up in Vercel to begin testing out these different use cases.
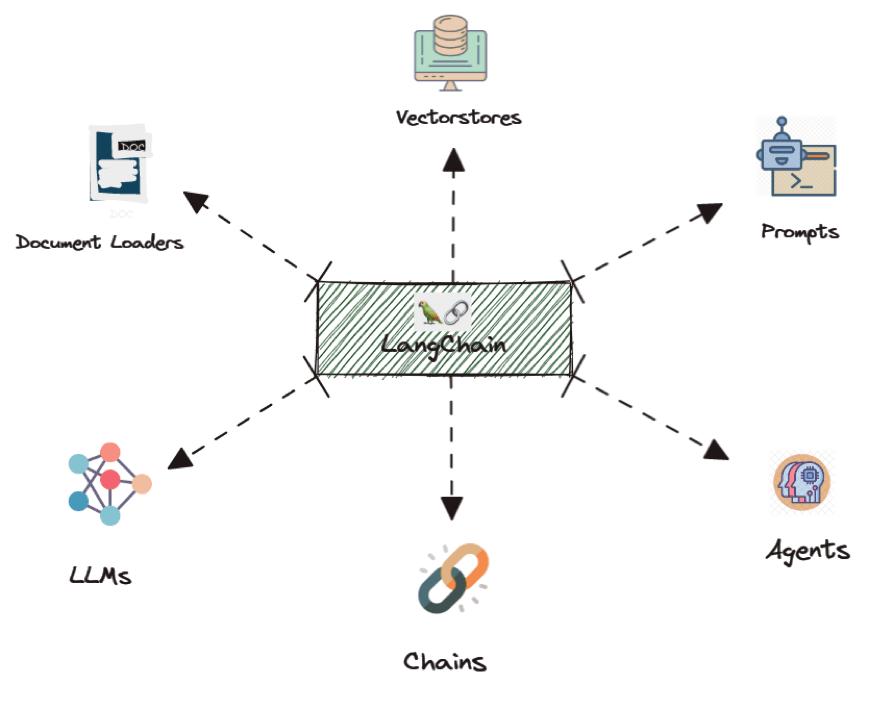
I’ll go into more detail about the different modules that are available with LangChain and use cases where they can be useful in a future blog post. For some of the Proof of Concepts I’m working on, I’m likely going to use LangChain because it’s feature-rich and easy to use.
Chat Interface
Finally, it’s briefly mentioned above, but you’ll need a chat interface, this can be pretty simple, so I won’t call it out specifically below. In our Microsoft Chat Copilot example in my previous post, this was simply a frontend React application running as a SPA, but you could build this with Angular, React/Next.js, .Net, Blazor, etc. It really doesn’t matter, just the application will connect typically via API to your Orchestrator/LLM SDK. So with that described let’s now take a closer look at each of the pieces more closely.


